100篇人工智能论文
- 论文大全
- 2026-06-19
- 417
AI/ML景观
这是一篇关于100篇 人工智能 论文的文章来帮助解开 人工智能 景观的神秘。最初的部分是关于基础知识,并提供一些重要的链接来加强你的基础。后一部分链接到一些伟大的研究论文,是为那些想了解理论和细节的高级实践者。
人工智能是一场正在改变人类生活和工作方式的革命。这是一个广义的概念,即机器能够以人类认为“智能”的方式执行任务——这个术语可以追溯到70年前(见这里的历史 /-today/---),艾伦·图灵定义了一个测试,图灵测试 ( /wiki/),用来测量机器表现出与人的智能行为相当或不可区分的智能行为的能力。革命有许多复杂的运动部分。我的目标是简化并提供一个关于这些复杂部分如何在一个3层蛋糕中组合在一起的观点。顶层是人工智能服务,即解决实际问题的真实应用程序,中间层是基本的ML算法,而底层是支持前两层的ML平台。
首先是基本定义,人工智能是由机器 ( /wiki/) 表现出来的智能( /wiki/),而不是由人类表现出来的自然智能。机器学习(ML)是人工智能的一个子集,它基于这样一种理念:我们应该真正能够让机器访问数据,让它们自己学习。神经网络(NN)是ML的一个子集,在ML中,计算机系统被设计成像人脑一样通过对信息进行分类来工作。深度学习(Deep ,DL)是ML的一个子集,它使用多层人工神经网络来解决诸如目标检测、语音识别和语言翻译等复杂问题。
关于AI、ML和DL之间的差异,可以在这里和这里找到一些很好的阅读资料。
神经网络的基础知识在这里和这里通过代码都有很好的解释。
人工智能可以根据这里解释的窄型、一般型或强型分类,也可以根据这里解释的反应机器、有限记忆、思维理论和自我意识的水平分类 。
ML算法
ML算法可以分为有监督、无监督和强化学习(这里 /list---/、这里 /types-of----you--know-和这里解释 /a-tour-of---/)。ML和DL在提取特征的方式上有所不同。传统的ML方法要求数据工作者通过应用学习算法显式地提取特征。另一方面,在DL的情况下,这些特性是由算法自动学习的,不需要特性工程——例如,来自的Meena ( /meena--new--) 新有26亿个特性。这是DL相对于传统ML方法的优势。
神经网络受到大脑神经元的启发,被设计用来识别复杂数据中的模式。我们大脑中的神经元被组织成数十亿个巨大的网络,每一个神经元通常与成千上万个其他神经元相连,通常是连续的一层,特别是在大脑皮层(即大脑外层)。神经网络有输入、输出和隐藏层。具有两个或多个隐藏层的神经网络称为深神经网络。
人工神经网络(ANN)模拟生物神经系统。一层的输出通过一个转换,使用函数成为下一层的输入。激活函数是附着在网络中每个神经元上的数学方程,根据每个神经元的输入是否与模型的预测相关,确定是否应该激活(“激发”)。激活函数可以是线性或非线性的。TanH,,ReLU,Leaky ReLU的关键激活功能在这里 ( /----) 和这里( /deep-study-of-a-not-very-deep---part-2---) 被解释。
这里 ( /types-of---and-what-each-one-does--)和这里 ( /---from--to-rnn-cnn-and-deep--) 解释了不同种类的ANNs。这里有一张完整的神经网络图 ( /the---chart-of----)。
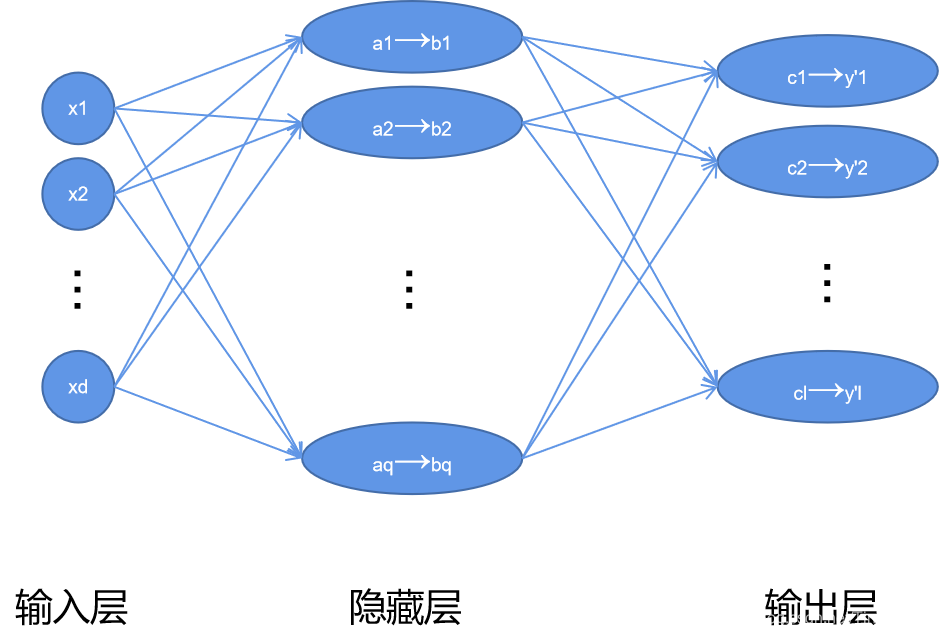
考虑到神经网络模型的复杂性和爆炸性,有相当大的努力使架构工程自动化,以找到针对给定业务问题的最佳机器学习模型设计神经架构搜索 ( /---nas-the--of-deep--)。这是和超参数优化的一个子领域。这里 ( /---nas-the--of-deep--) 还有这里 ( /-you-need-to-know-about--and----)。
ML平台
一个重要的努力不是花在创新新的学习算法或模型上,而是花在改进ML工具和基础设施上。ML平台为机器学习开发人员、数据科学家和数据工程师提供了基础,使他们能够快速、经济高效地将ML项目从构思到生产和部署。
ML生命周期
典型的ML生命周期从数据准备开始,然后是(特性)发现、开发和培训模型、测试、部署,最后使用模型进行推断或预测。数据准备通常与获取、推导和清理足够的训练数据以输入ML算法有关。功能发现和提取识别对业务领域最重要的关键数据属性。部署包括可观测性、可调试性、监控和生产化。这里可以找到Auto-ML框架 ( /--blog/-the-best---)的特定于云的基准 ( /pdf/1808.06492.pdf)。
在现代的ML生命周期中有几个挑战(见技术债务 Debt. /paper/5656---debt-in---.pdf)。
MxNet( /~muli/file/mxnet--sys.pdf) ( /paper/.pdf) ( //files///-.pdf) Caffe( /pdf/1408.5093.pdf) ( /paper/9015--an--style-high--deep--.pdf) ( /pdf/1605.02688.pdf) ( /pdf/1908.00213.pdf)
( /~matei//2018/.pdf)斯坦福大学的开源项目()和DAWN项目 ( /pdf/1705.07538.pdf)(Data for what next)正试图解决这些挑战。
的关键原则是开放式界面设计,与现有的ML平台如...
参见此处的比较( /five-open-----to-build---at-scale-)
相比,这种开放式界面设计在保留生命周期管理优势的同时,为用户提供了灵活性和控制能力。DAWN堆栈除了解决ML生命周期的挑战外,还解决了从新接口到新硬件的抽象。
ML Stack
AI/ML ArkAI Stack ( //page//4575)
1) 计算硬件-一个很好的看法,计算硬件-CPU,GPU和TPU-可以在这些文件中找到从 ( /wp-//2017/12/hpca-2018-.pdf) 和谷歌 ( /pdf/1704.04760.pdf)。量子物理( /----new--for------)与ML( /----new--for------)的交叉产生了量子机器学习 ( /----new--for------)。最近开放源码的 ( /),用于使用 Cirq等框架快速成型混合经典量子模型( //Cirq)。
2) 具有高度并行性的分布式深度学习运行模型需要并发性(见分析) ( /pdf/1802.09941.pdf)和调度程序(DL2 ( /pdf/1909.06040.pdf)、 ( i.cs.hku.hk/~cwu//-.pdf)和( //files/-gu.pdf))。在构建分布式深度学习框架方面有很多进展,这里有一个很好的介绍,其中最受欢迎的是 GPIPE ( /pdf/1811.06965.pdf)、Uber ( /pdf/1802.05799.pdf)、的TF ( /pdf/1902.00465.pdf) 和微软的 ( /pdf/1806.03377.pdf) Zero&&( /en-us//blog/zero--new------with-over-100--/)。
3) 功能存储允许不同的团队管理、存储和发现用于机器学习项目的功能。它充当数据工程和数据科学之间的API,支持改进的协作。这里有一个很好的介绍 ( /what-are---and-why-are-they--for--data--),其中列出了一些特色商店。
* 来自谷歌的Feast ( [https://cloud.google.com/blog/products/ai-machine-learning/introducing-feast-an-open-source-feature-store-for-machine-learning](https://cloud.google.com/blog/products/ai-machine-learning/introducing-feast-an-open-source-feature-store-for-machine-learning)), ( [https://towardsdatascience.com/using-feast-to-centralize-feature-storage-in-your-machine-learning-applications-dfa84b35a1a0](https://towardsdatascience.com/using-feast-to-centralize-feature-storage-in-your-machine-learning-applications-dfa84b35a1a0))
* LogicalClocks公司的HopesWorks ( [https://uploads-ssl.webflow.com/5e6f7cd3ee7f51d539a4da0b/5e6f7cd3ee7f519fdfa4dadb_feature%20store%20whitepaper%201-0.pdf](https://uploads-ssl.webflow.com/5e6f7cd3ee7f51d539a4da0b/5e6f7cd3ee7f519fdfa4dadb_feature%20store%20whitepaper%201-0.pdf))
* LinkedIn的Frame ( [https://www.slideshare.net/DavidStein1/frame-feature-management-for-productive-machine-learning](https://www.slideshare.net/DavidStein1/frame-feature-management-for-productive-machine-learning))
* Airbnb的ZipLine ( [https://databricks.com/session/zipline-airbnbs-machine-learning-data-management-platform](https://databricks.com/session/zipline-airbnbs-machine-learning-data-management-platform))
* ML Ops ( [https://towardsdatascience.com/mlops-with-a-feature-store-816cfa5966e9](https://towardsdatascience.com/mlops-with-a-feature-store-816cfa5966e9))可以与一个特性存储相结合,以自动化模型的培训、测试和部署。4) 可解释性和可解释性-人工智能系统中信任的4个特征是i)模型和数据没有偏见的公平性ii)稳健性,不易篡改或损害他们接受过培训的数据iii)决策可以被消费者理解的可解释性iv)允许审核模型生命周期的开发、部署和维护。这些技术中最突出的是LIME和SHAP ( /idea--lime-and-shap-),它们基于模型不可知的方法,这些方法专注于解释给定黑盒分类器的单个预测。局部可解释模型不可知解释(LIME)提供了一种快速的方法,它通过随机地迭代扰动模型特征来获得预测,然后利用预测计算近似的线性“解释模型”。SHAP(加法解释)通过计算每个特征对预测的贡献来工作。它起源于联合博弈理论,其中数据实例的每个特征值充当联盟中的参与者,并计算每个特征的边际贡献或支出(参见Chris 的《可解释机器学习》一书 ..io/-ml-book/)。这里很好地描述了这两种技术之间的进一步差异 ( /ibm-/-black-box---and-deep--using-lime-and-shap-)。谷歌的可扩展性白皮书也是一个很好的参考 ( /cloud-ai-/AI%%.pdf)。
为了消除偏见 ( /how-to--bias-in-ai-),最近引入了两种新的方法,即用概念激活向量(TCAV /tcav-----)和联合学习进行测试。TCAV从实例数据中学习概念。例如,TCAV需要实例数据中的几个女性示例,以学习“性别”概念。人类用概念思考和交流,而不是对每个特征使用权重。TCAV以人类相互交流的方式提供解释。联合学习 ( /2017/04/--.html)将模型训练推向了边缘(以移动计算为例)。
5) 可视化-与模型的可解释性和可解释性相关的是模型可视化。白盒 ( //-to-the-white-box-ai-the--of--)人工智能着眼于模型复杂度和模型感知,提出了不同的可视化技术 ( //white-box-ai---)。谷歌开源 ( /2017/07/-open---tool.html)有助于培训数据的可视化,Uber在内部使用 ( /pdf/1808.00196.pdf),而有 ( /blog/-high---plots-made-easy/)。
6) 度量-度量用于度量模型的质量和性能。有许多不同类型的评估指标可用于测试模型。包括混淆矩阵、分类准确度、精密度、召回率、ROC、AUC、F1评分、敏感性、特异性、对数损失、均方误差和绝对误差。这个由三部分组成的系列是一个很好的参考 ( ..io/blog/2019/04/11/ml-model---p1)。另一个介绍性的参考资料在这里 ( /20-----part-1-----)。就模型预测而言,偏差和方差之间存在一种权衡,这种权衡可能是由于拟合不足或拟合过度造成的 ( /-the-bias---)。为了建立一个好的模型,你需要通过在偏差和方差之间找到一个好的平衡来最小化总误差。另一个需要测量的重要问题是概念漂移和模型衰减 ( /-drift-and-model-decay-in---)。当输入和输出数据之间的关系随着时间的推移而改变时,概念漂移就发生了( /---drift--/),这意味着在较旧数据上训练的模型不再像在较新数据上训练的那样精确。防止模型衰减的一个好方法是持续监视和维护它 ( /why-----in--)。
最后,下一节是为一个人工智能技术专家谁是感兴趣的建设和扩展ML算法和平台。
上一篇:数脉
发表评论